Visual Computing Lab
University of Wisconsin–Madison · September 2012 – August 2013
Research Intern · Visualization Design, Web and Python Development
Professor Michael Gleicher hired me to work as a research intern on the Visualizing English Print project (VEP), a group working on data visualization tools to explore and find new insights in a corpus without having to read every text.
I worked with Professor Gleicher, Eric Alexander, and Associate Professor Robin Valenza on two literary visualization projects:
Serendip+Ity: a tool for visually exploring and finding patterns in large text corpora using topic models.
Ubiqu+Ity: a web service that lets researchers tag and explore their own text files using a dictionary of linguistic patterns named DocuScope.
Serendip+Ity
August 2012 - April 2013
with Eric Alexander, Michael Gleicher, and Robin Valenza
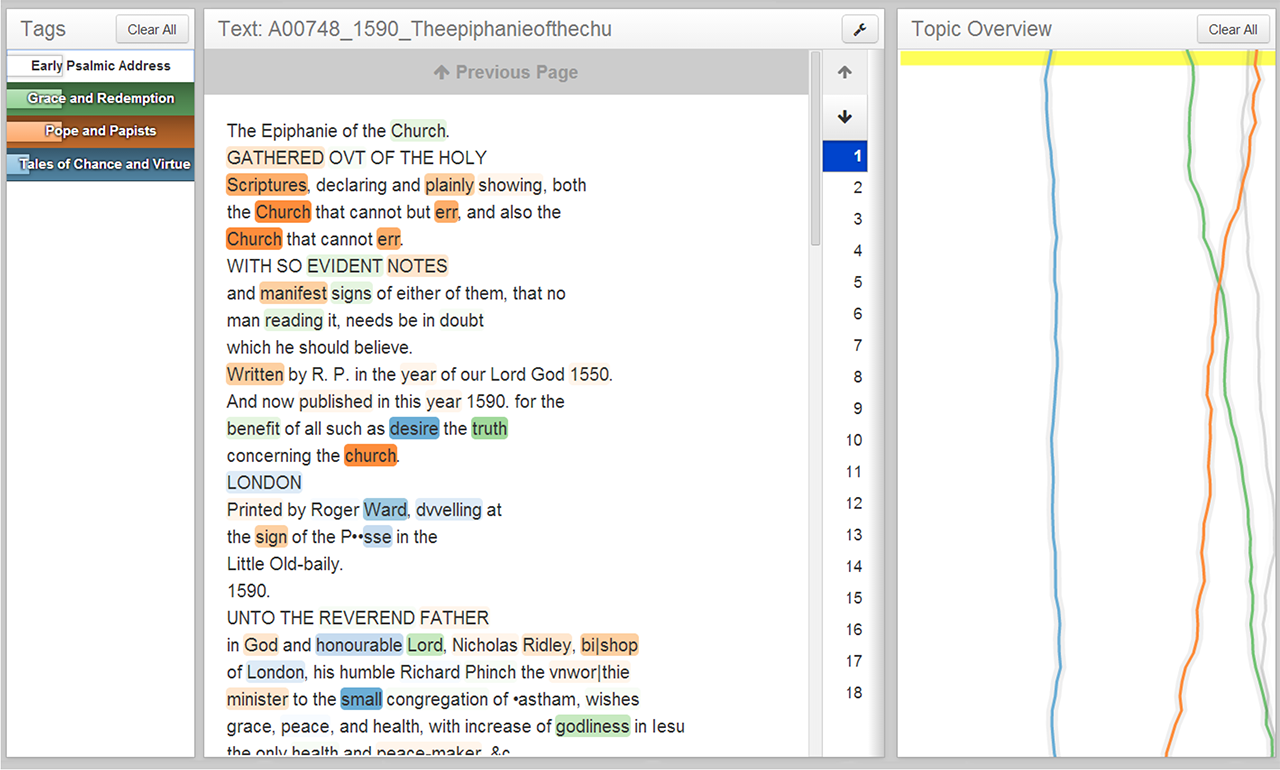
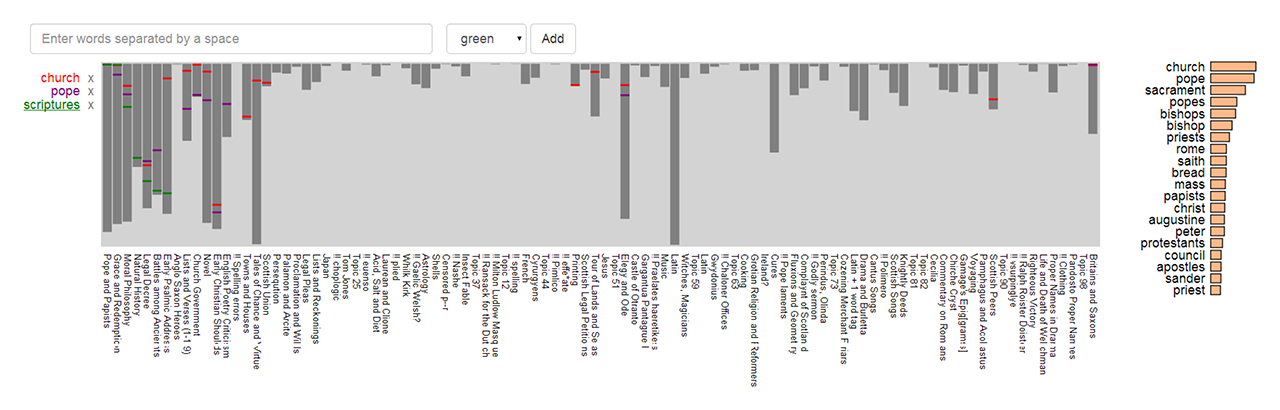
Serendip+Ity is a web app which enables the visual exploration of large text corpora. Using topic models and other metadata, it lets researchers investigate language usage patterns, at multiple levels of abstraction, across thousands of texts.
The new visualization techniques and statistical methods implemented in Serendip+Ity help literary scholars efficiently analyze multiple data sources at scale. We accomplish this by providing customizable summary controls and by creating visual links between views, making it possible to track corpus-level trends down to individual passages.
VAST 2014 Publication
In addition to front and back-end development, I also supported our publication efforts through the creation of graphics and a video demonstration for our VAST 2013 submission.
After leaving the Visual Computing Laboratory for grad school, findings from an updated version of Serendip+Ity were presented at the VAST 2014 conference.
E. Alexander, J. Kohlmann, R. Valenza, M. Witmore, and M. Gleicher. Serendip: Topic model-driven visual exploration of text corpora. In Proc. IEEE Conference on Visual Analytics Science and Technology, 2014.
Ubiqu+Ity
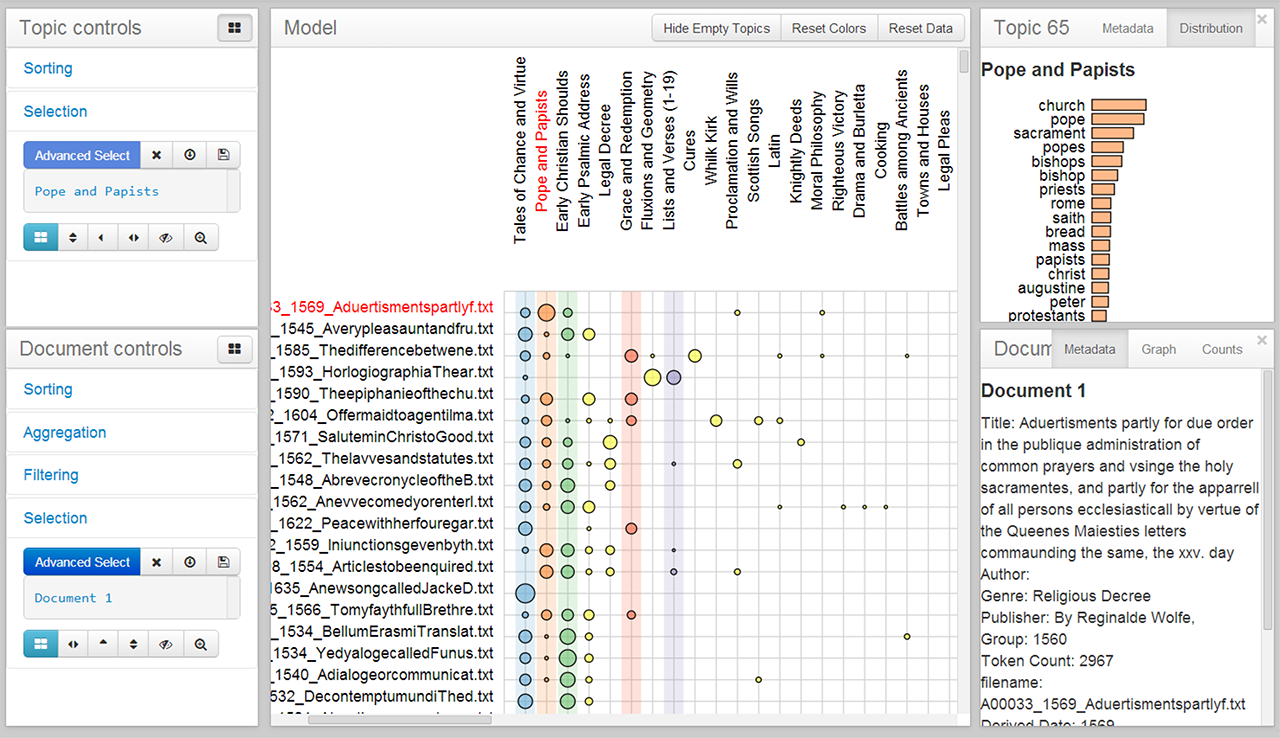
Our work on Serendip+Ity led to a library of Python modules for normalizing, tagging, and formatting texts with a level of customization required to build our visualizations. We reused this library to create Ubiqu+Ity, a web service that lets researchers upload texts for tagging with a dictionary of linguistic patterns named DocuScope.
Our goal with Ubiqu+Ity was to let researchers tag texts with DocuScope without needing the dictionary or the tools required to apply it. We also wanted the output to function without an Internet connection. Hence, we built a web service which delivers each of the tagged texts as a self-contained HTML file, containing the data and application itself.
See also: the Ubiqu+Ity home page, where you can use the service, and the source code on GitHub.